Understanding why and how to add idempotent requests to your APIs
Table of Contents
Idempotency is an often used term in computer science. It’s meaning to some might not be known, to others it’s very well known. The explanation for idempotency on Wikipedia is:
… the property of certain operations in mathematics and computer science that they can be applied multiple times without changing the result beyond the initial application.
Essentially, idempotency is the mathematical way of saying “one can apply a certain operation on something many times, without changing the result of the operation after the first time the operation is applied”.
A common example of this would be an UPDATE statement in SQL. For example,
imagine you have a SQL table full of student’s first and last names, like in a
school system. Updating a name of a student, would look like this:
UPDATE students SET first_name = 'John' WHERE id = 123;Applying this query is idempotent, because the first time you run it it will
update the name of student with id 123, but if you run it a milion times more
after, the result will not change - the name will still stay John.
Let’s think a bit about APIs now. Imagine you have an API to do bank transactions, what would happen if in the middle of a API call for performing a transaction the server throws an exception and the call fails? What if the client crashes and it never receives the message? Or, what if the connection drops mid-way and the client never gets the response of the server, but the server executes the transaction?
As you can imagine, there can be many causes of an API call failing, but how would we know if the operation failed or it succeeded? How would we known if a transaction went through, or not?
Imagine if our APIs were smart enough so we could selectively make calls to the API idempotent?
The problem at hand #
I work in Catawiki, where we do auctions. For those not familiar with auctions - auctions are group of items (called lots) that people can bid on during a period of time. Bidding is the process of offering up a price for an item, within the aforementioned time period.
If you are reminded of early eBay days, that’s perfect. Knowing about how eBay used to work back in the day is enough knowledge about auctions you need for this blog post.
So people come to the website, they browse through the various auctions running, they view the items they would like to own and they bid on them. As you can imagine, placing a bid on an item is the most important action in an auction site and the user must know when their bid has been accepted (or not). So, what would happen if the request dies in mid-flight? Or maybe our user’s browser gets stuck, and the user tries to click multiple times on the bid button while the browser sits unresponsive.
How can we know if the actual bid was placed or not?
Idempotent APIs #
When we are dealing with similar systems, one of the way one could tackle this problem is designing APIs that have the ability to be idempotent. Since we already established what idempotency means, idempotent APIs are APIs where any write operations can have effect only once for a given set of parameters.
In fact, some companies have already implemented solutions for this, and one of the better examples out there is Stripe.
Stripe’s API does that via a HTTP header, called Idempotency-Key, which is a
random set of characters. An example cURL request looks like this:
curl https://api.stripe.com/v1/charges \
-u sk_test_BQokikJOvBiI2HlWgH4olfQ2: \
-H "Idempotency-Key: AGJ6FJMkGQIpHUTX" \
-d amount=2000 \
-d currency=usd \
-d description="Charge for Brandur" \
-d customer=cus_A8Z5MHwQS7jUmZAs you can imagine, just like with bidding, designing APIs whose consumers can do actual money transactions are quite important to be very safe from various failures, especially where the sending or the receiving party cannot process the request/response fully.
So, how could we design and implement an idempotent API solution for our auctions website? Let’s start off by some wishful thinking.
curl https://api.example.com/v1/item/:item_id/bid \
-X POST \
-H "X-Auth-Token: BGT9FJMkd1Ow" \
-H "Idempotency-Key: AGJ6FJMkGQIpHUTX" \
-d amount=2000Our API would have an endpoint, called POST /v1/item/:item_id/bid, which
would create a bid for our item on auction. The request, in it’s payload, would
contain the amount for the bid, and in the headers it would contain the API
token and the idempotency key.
Simple enough for a first iteration of our solution, but complicated just enough to do the trick for us.
Adding the endpoint #
In our simple example auction application, we’ll have the following models (and respective associations):
class Auction < ApplicationRecord
has_many :lots
end
class Lot < ApplicationRecord
has_many :bids
belongs_to :auction
end
class Bid < ApplicationRecord
belongs_to :lot
belongs_to :user
validates :amount, presence: true, numericality: true
end
class User < ApplicationRecord
has_many :bids
endPersonally, I am used to using Grape on a daily basis to build REST APIs with, so the syntax you will be seeing here will be from Grape. But the general approach and solution can be transfered to other frameworks and languages.
Our endpoint would look something like this:
module API
module V1
module Lots
class Bids < Grape::API
resource :lots do
route_param :lot_id do
params do
requires :lot_id, type: Integer, desc: 'Lot ID'
end
resource :bids do
params do
requires :amount, type: Integer, desc: 'Amount'
end
desc 'Create a bid for a lot'
post do
lot = Lot.find(params[:lot_id])
lot.bids.create!(amount: params[:amount])
body false
end
end
end
end
end
end
end
endAs you can notice, this is a very simple endpoint. It’s URI is POST /lots/:lot_id/bids, and in the request body it accepts the amount of the bid
as an integer. If you would like to see how the endpoint performs, you can
fetch the repo, set it up locally and play
with it.
The first step to adding idempotency token support is to be able to easily send it. If you are using a API browser like Postman or Paw, you have that ability out of the box. These API browsers allow us to send any type of params or headers. For example, this is what a successful request to this endpoint looks like, via Postman:
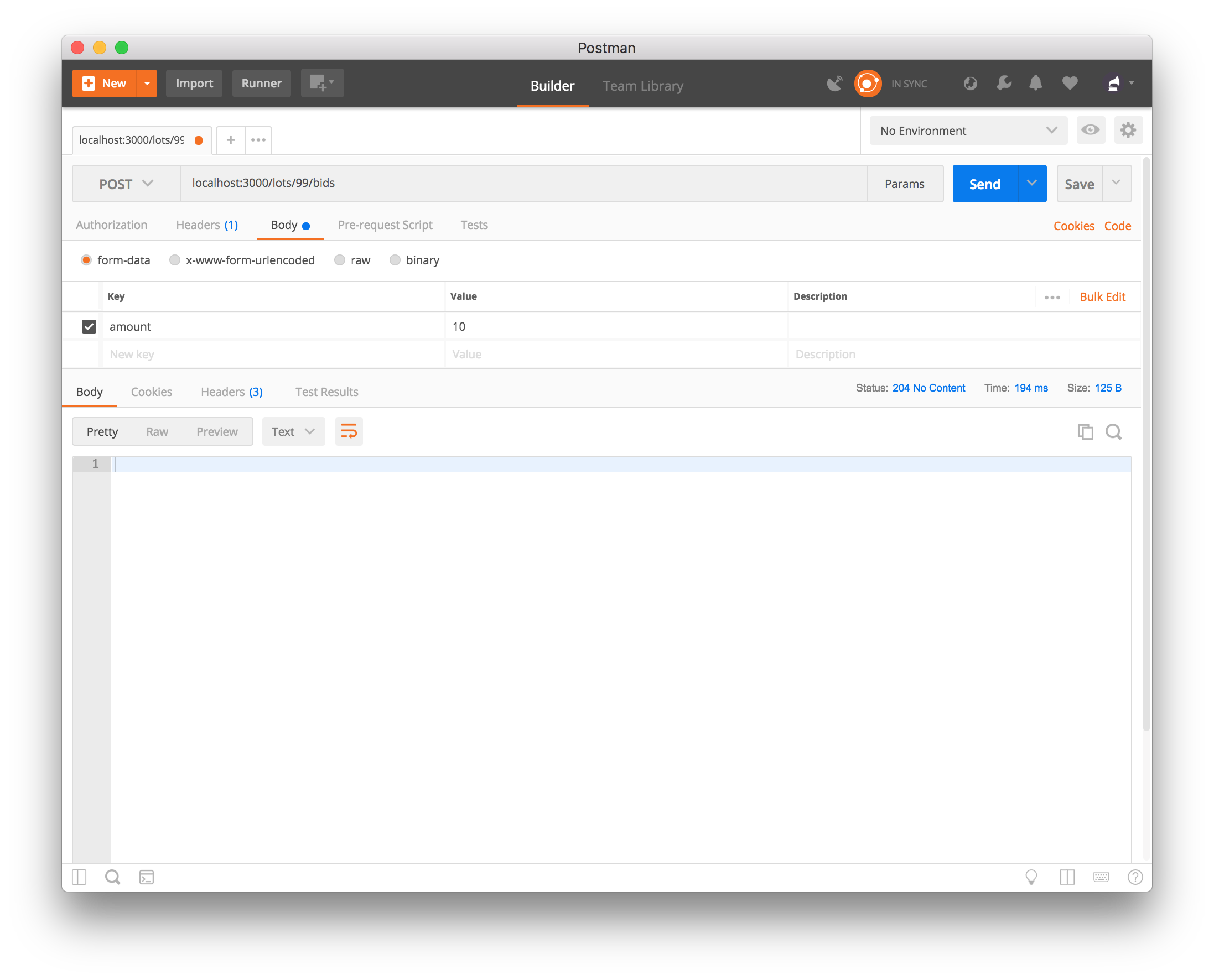
As you can notice, we explicitly set the endpoint to return no body which will set the HTTP status to 204, therefore providing enough context if and when the bid is accepted by the system.
The internals of the endpoint are quite simple - we find the lot by the
lot_id from the URI, and we create a Bid for it with the amount sent in
the params. No magic, very simple endpoint.
As you can imagine, when bidding for an item on auction, every bid has to be
bigger than the previous one. Therefore, adding a validation on the Bid model
to do these kind of checks is required. This is what our Bid model will look
like:
class Bid < ApplicationRecord
belongs_to :lot
validates :amount, presence: true, numericality: true
validate :amount_larger_than_previous_bid
private
def amount_larger_than_previous_bid
return true if lot.bids.none?
return true if amount > lot.bids.last.amount
errors.add(:amount, 'must to be larger than previous bid')
end
enIn the model, the Bid#amount_larger_than_previous_bid method will do this
check for us, and add the appropriate errors to the amount attribute, if
needed. If we try to send another bid to the same lot from before, this is
what we will get back:
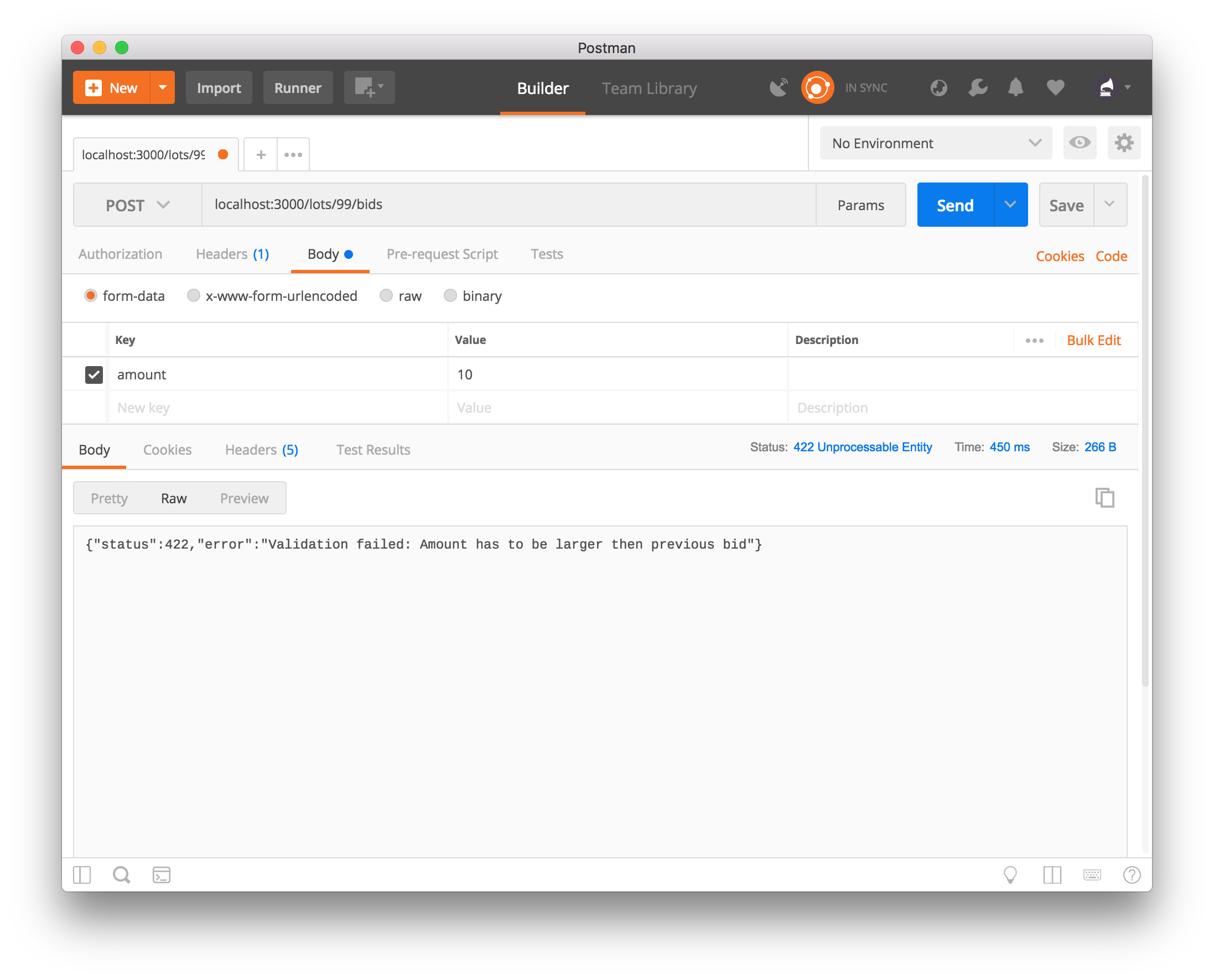
Introducing the key #
Adding the key to the header, from the perspective of the client, is a very simple feat. Postman, just like any standard HTTP library, allows us to set the headers to our requests. For example, in Postman that would look like:
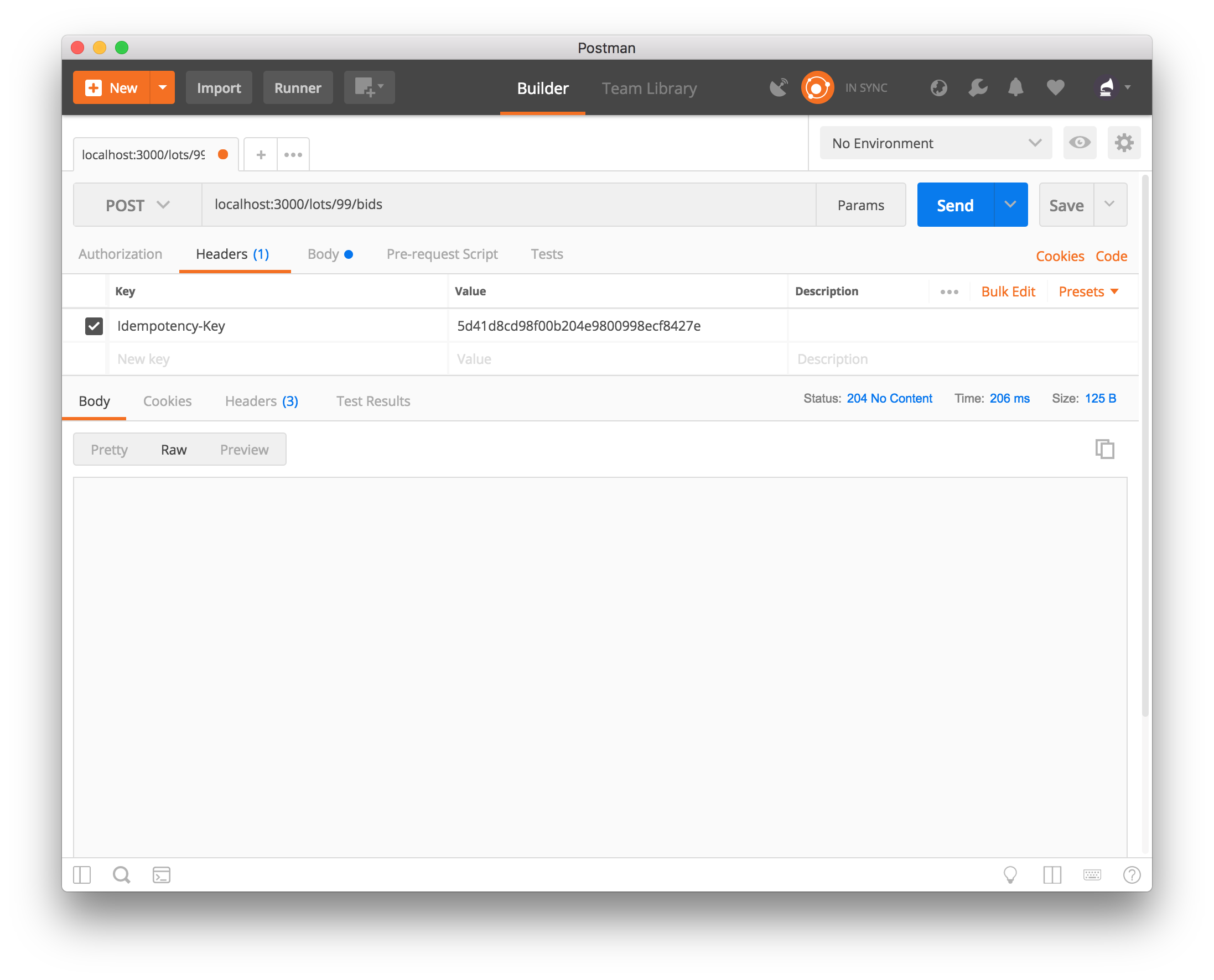
This will apply the Idempotency-Key header to the request, for our API to
pick up and validate. So, how would our API accomplish this?
In cases like this one, I personally prefer opaque approaches, meaning, an approach that the stack can work with without any additional hassle to the daily work of the developers of the APIs. One of those approaches is by adding a middleware that will take care of logging the idempotency keys and returning the saved responses.
But, before we jump in to the middleware, we have to think of how we can store the headers that will be used, and the responses that will be coupled to each of these idempotency headers.
Of course, the simplest solution that we could work with is using our database.
I already feel some of you frowning at this and saying “WTF is wrong with this
guy?!”. I agree, this is not even near optimal, but bear with me for the sake
of the example. Let’s introduce a tiny IdempotentAction model, which will
have idempotency_key, body, headers and status attributes.
class IdempotentAction < ApplicationRecord
validate_presence_of :idempotency_key, :body, :status, :headers
endThis will do it for now. This model can store all of the idempotency keys that have been sent to the API, together with the body, status and headers of the response. Now, back to the middleware.
We want whenever a client of our APIs sends a request using a Idempotency-Key
header to check if that key has been used (and return the saved response if so)
or save a new entry to our table with idempotent requests and respond with the
response of the API.
Let’s take a look at skeleton of this middleware:
# lib/idempotent_request.rb
class IdempotentRequest
IDEMPOTENCY_HEADER = 'HTTP_IDEMPOTENCY_KEY'.freeze
def initialize app
@app = app
end
def call env
dup._call env
end
def _call env
idempotency_key = env[IDEMPOTENCY_HEADER]
if idempotency_key.present?
# Check if action has been persisted
else
@app.call(env)
end
end
endThis middleware will check each of the requests coming in to the application,
fetch if the Idempotency-Key is present in the headers and based on that do a
certain action. Let’s see what those actions will be:
class IdempotentRequest
IDEMPOTENCY_HEADER = 'HTTP_IDEMPOTENCY_KEY'.freeze
def initialize app
@app = app
end
def call env
dup._call env
end
def _call env
idempotency_key = env[IDEMPOTENCY_HEADER]
if idempotency_key.present?
action = IdempotentAction.find_by(idempotency_key: idempotency_key)
if action.present?
status = action.status
headers = Oj.load(action.headers)
body = Oj.load(action.body)
else
status, headers, response = @app.call(env)
response = response.body if response.respond_to?(:body)
IdempotentAction.create(
idempotency_key: idempotency_key,
body: Oj.dump(response),
status: status,
headers: Oj.dump(headers)
)
end
[status, headers, body]
else
@app.call(env)
end
end
endIf the header is present in the request, we will query the database for and
check if there’s a IdempotentAction entry present. If it is, the middleware
will stop any futher execution in the middleware stack (a.k.a. the rest of the
application) and will immediatelly respond with the saved body, status and
headers.
Otherwise, it will make sure it proceeds with the chain of execution, and after
all of the request is fulfilled it will store the body, status and
headers in a IdempontentAction entry in the database. By doing that any
subsequent request using the same Idempotency-Key header will result in the
previous response, regardless of the body, URI or params of the request.
Mounting this middleware is as easy as adding this line to the application’s
config/application.rb file:
module MyApp
class Application < Rails::Application
# snipped
config.middleware.use IdempotentRequest
end
endNow, if we send a request to our endpoint to create a bid for a lot, with an
Idempotency-Key header, in our server logs we will see something like:
Started POST "/lots/99/bids" for 127.0.0.1 at 2017-10-28 01:19:35 +0200
IdempotentAction Load (0.2ms) SELECT "idempotent_actions".* FROM "idempotent_actions" WHERE "idempotent_actions"."idempotency_key" = ? LIMIT ? [["idempotency_key", "5d41d8cd98f00b204e9800998ecf84272"], ["LIMIT", 1]]
Lot Load (0.1ms) SELECT "lots".* FROM "lots" WHERE "lots"."id" = ? LIMIT ? [["id", 99], ["LIMIT", 1]]
(0.1ms) begin transaction
Bid Exists (0.3ms) SELECT 1 AS one FROM "bids" WHERE "bids"."lot_id" = ? LIMIT ? [["lot_id", 99], ["LIMIT", 1]]
Bid Load (0.2ms) SELECT "bids".* FROM "bids" WHERE "bids"."lot_id" = ? ORDER BY "bids"."id" DESC LIMIT ? [["lot_id", 99], ["LIMIT", 1]]
SQL (0.4ms) INSERT INTO "bids" ("lot_id", "amount", "created_at", "updated_at") VALUES (?, ?, ?, ?) [["lot_id", 99], ["amount", 153], ["created_at", "2017-10-27 23:19:35.787067"], ["updated_at", "2017-10-27 23:19:35.787067"]]
(1.0ms) commit transaction
(0.1ms) begin transaction
SQL (0.6ms) INSERT INTO "idempotent_actions" ("idempotency_key", "body", "status", "headers", "created_at", "updated_at") VALUES (?, ?, ?, ?, ?, ?) [["idempotency_key", "5d41d8cd98f00b204e9800998ecf84272"], ["body", "[\"\"]"], ["status", 204], ["headers", "{}"], ["created_at", "2017-10-27 23:19:35.792024"], ["updated_at", "2017-10-27 23:19:35.792024"]]
(1.0ms) commit transactionAs you can tell, the middleware kicks in, picks up the header value and checks
for a possible entry in the IdempotentAction model. Then, it proceeds with the
exectuion of the request, and afterwards it persists the response with the
key in the table. Any subsequent request with the same Idempotency-Key will
produce a log like:
Started POST "/lots/99/bids" for 127.0.0.1 at 2017-10-28 01:22:09 +0200
IdempotentAction Load (0.2ms) SELECT "idempotent_actions".* FROM "idempotent_actions" WHERE "idempotent_actions"."idempotency_key" = ? LIMIT ? [["idempotency_key", "5d41d8cd98f00b204e9800998ecf84272"], ["LIMIT", 1]]That’s it! The middleware will pick up the record from the database and it will send the response immediatelly.
Although the idempotent requests mechanism is interesting, keeping all of these keys can be expensive, especially if you do it in an nonoptimal way like by using the database. Whenever you are in doubt if data like this should be stored in a database, always think about how crucial to your business this data is. For the scope of our example, this data is not business critical, therefore we could offload it to a different type of storage.
What would be a cheap way of storing these idempotency keys?
Swapping the storage #
A very cheap way of persisting these keys is, believe it or not, by putting
them (programatically) in a file. Ruby as a language provides couple of
key-value store solutions, like PStore and YAML::Store. I personally prefer
YAML::Store
because it would allow us to read the contents of the file it writes to, unlike
PStore which writes the files in binary format.
If you’ve never used YAML::Store, think of it as a streamlined approach to
writing/reading to a file using YAML. Let’s briefly open an irb session and
play a little bit with YAML::Store:
>> require 'yaml/store'
=> true
# Open a new store
>> store = YAML::Store.new('file_to_write_in.yml')
=> #<Psych::Store:0x007fbf83d3e0d8 @opt={}, @filename="file_to_write_in.yml", @abort=false, @ultra_safe=false, @thread_safe={}, @lock=#<Thread::Mutex:0x007fbf83d3de30>>
# Write something to the store
>> store.transaction { store['name'] = 'Ilija Eftimov' }
=> "Ilija Eftimov"
# Read something from the store
>> store.transaction(false) { store['name'] }
=> "Ilija Eftimov"Now, if we check our file where our store is writing to, we will see something like:
---
name: Ilija EftimovYAML is super flexible and will know how to marshall different type of objects
into YAML. Also, when you want to read from the store, it will unmarshall them
back and create objects with their properties.
After that quick crash course in YAML::Store, let’s get back to our middlware.
This is what it would look like, if we use YAML::Store as a storage engine:
require 'yaml/store'
class IdempotentRequest
IDEMPOTENCY_HEADER = 'HTTP_IDEMPOTENCY_KEY'.freeze
STORE_FILE_PATH = 'idempotency_keys.store'.freeze
attr_reader :store
def initialize app
@app = app
@store = YAML::Store.new(Rails.root.join(STORE_FILE_PATH))
end
def call env
dup._call env
end
def _call env
idempotency_key = env[IDEMPOTENCY_HEADER]
if idempotency_key.present?
action = store.transaction(false) { store[idempotency_key] }
if action.present?
status = action[:status]
headers = action[:headers]
response = action[:response]
else
status, headers, response = @app.call(env)
response = response.body if response.respond_to?(:body)
store.transaction do
store[idempotency_key] = {
status: status,
headers: headers.to_h,
response: response
}
end
end
[status, headers, response]
else
@app.call(env)
end
end
endCompared to our database solution, the YAML::Store solution is a bit simpler,
and more lightweight. As you can notice, the approach is the same - we check if
our store already has the idempotency key persisted, and if so we return the
saved status, headers and response. Otherwise, we let the middleware chain
finish executing, and then we persist the idempotency key with the response data
to the store.
As with any other solution, this approach has couple of pros and cons. As you can imagine, saving this data to a file is not really reliable. Backing up the file, although it seems simple, it can be quite error prone compared to the already provided solutions to backing up databases. Also the more traffic our service gets, the disk I/O would increase quite a bit, therefore the solution would not scale too far into the future.
On the other hand, this solution has no dependency on a database, nor on Active
Record. It does have a dependency on YAML::Store, but that one is much cheaper
to load to your application because it doesn’t have other dependencies that it
needs to run (except YAML, which is already loaded by default in your Rails
apps). From a code perspective, it’s very simple - it feels like saving to a
hash that automatically gets dumped onto disk. It requires no additional models,
schemas or migrations.
Expiring the keys #
Whenever we store this type of data, a good idea is to clean up the used keys after a certain period of time, because the responses that they have stored are already stale and unusable for the clients. Therefore, cleaning this from a relational database or a YAML file will require custom solution, for example, in the form of a scheduled job that would scrape off all the stale keys. Or maybe in another way, still by adding more and more code to our codebase that we would need to maintain.
Or, we could change our storage, again?
When it comes to storing keys with values the most popular choice (with a good reason!) is Redis. It is riddiculously fast in what it does, writing and reading to it with Ruby is very simple, and it even provides a TTL (Time To Live) which means it will automatically expire our stale keys without us writing a single line of code. Of course, Redis provides much more, but for the purpose of this article, it seems to fit just like a glove.
Note: If you are unfamiliar with Redis, I would recommend giving a shot at their interactive course to get yourself faimilar with the basics of Redis.
Connecting to Redis #
To communicate with Redis via a Rails app, we need to add the redis gem to our
bundle. After installing the gem via bundle install, we can immediatelly
connect to our local Redis instance without any special configurations. If you
are following this tutorial, but haven’t installed Redis yet, you can go over
to their download page and install it from there.
If you are running OSX, you can install it via Homebrew by installing the redis formula.
Having Redis running locally, and the redis gem in our app’s bundle, we can proceed to update our middleware to work with Redis.
Organizing and storing the data #
We can store our keys in
a hash structure, where the key will
be the idempotency key, and the value in the hash will be a serialized hash that
will contain the status, headers and body of the response. For example:
# Key : Serialied Hash
"1753ae4677": "{\"status\":204,\"headers\":{},\"response\":[\"\"]}"
"d3894c01c0": "{\"status\":422,\"headers\":{\"Content-Type\":\"text/plain\",\"Content-Length\":\"85\"},\"response\":[\"{\\\"status\\\":422,\\\"error\\\":\\\"Validation failed: Amount has to be larger then previous bid\\\"}\"]}"As you can see, both the key and the value are strings, where the value is the JSON serialized hash of the data we need. If you are wondering why JSON - it’s because serializing is very fast (with Oj) and it’s (somewhat) readable when it’s serialized therefore easy to access in Redis and explore/debug.
Let’s modify our middleware to work with Redis:
module IdempotentRequest
IDEMPOTENCY_HEADER = 'HTTP_IDEMPOTENCY_KEY'.freeze
REDIS_NAMESPACE = 'idempotency_keys'.freeze
attr_reader :redis
def initialize app
@app = app
@redis = ::Redis.current
end
def call env
dup._call env
end
def _call env
idempotency_key = env[IDEMPOTENCY_HEADER]
if idempotency_key.present?
action = get(idempotency_key)
if action.present?
status = action[:status]
headers = action[:headers]
response = action[:response]
else
status, headers, response = @app.call(env)
response = response.body if response.respond_to?(:body)
payload = payload(status, headers, response)
set(idempotency_key, payload)
end
[status, headers, response]
else
@app.call(env)
end
end
private
def get(key)
data = redis.hgetall namespaced_key(key)
return nil if data.blank?
{
status: data['status'],
headers: Oj.load(data['headers']),
response: Oj.load(data['response'])
}
end
def set(key, payload)
redis.hmset namespaced_key(key), *payload
end
def payload(status, headers, response)
[
:status, status,
:headers, Oj.dump(headers.to_h),
:response, Oj.dump(response)
]
end
def namespaced_key(idempotency_key)
"#{REDIS_NAMESPACE}:#{idempotency_key}"
end
endIf you’ve been reading the code so far in our previous solutions, the approach
is literally the same, only the way we store and read the data changes, from
both storage and code perspective. This time, we use Oj.dump to serialize and
Oj.load to deserialize our object to/from JSON. Also, storing the data is done
by calling the redis client, namely the
hmset and
hget methods.
redis.hget REDIS_NAMESPACE, keyhget will execute a HGET command in Redis, which will get the hash that
is stored under the REDIS_NAMESPACE value (in our case idempotency_keys),
and will access the key with the value of key. If present, this will retrieve
the serialized JSON object, or nil if not present.
redis.hmset REDIS_NAMESPACE, key1, payload1, key2, payload2hmset will execute a HMSET command in Redis, which will set a new key in the
hash, where the key will be the value of key1, and the value will be the hash
that payload1 is assigned to. The same key - value pair arguments scheme
continues for the rest of the arguments.
TTL #
One of the great features of Redis are called “Redis expires”. What that means is that basically you can set a timeout for a key, which is a limited time to live (TTL). When the time to live elapses, the key is automatically destroyed.
So, how can we leverage Redis expires to our advantage? Well, the first question that would pop up in my mind is for how long do we want to keep these keys/responses in our database? Ideally, the answer to this question is: short. Although this mechanism of saving the data can be very useful, if the data is not expired after a certiain period of time, you are looking at an unneeded complexity from data warehousing, security and scaling pespective. Also, most of the data that will not be expired will be stale, because it will be relevant until the client understands that the idempotent request has been fulfilled and will move on with it’s operations.
Therefore, adding a TTL on the key is not a silver bullet, but for most of the cases it’s a very good idea. Let’s see how we can update our middleware to set the correct TTL on the Redis keys:
module IdempotentRequest
IDEMPOTENCY_HEADER = 'HTTP_IDEMPOTENCY_KEY'.freeze
REDIS_NAMESPACE = 'idempotency_keys'.freeze
EXPIRE_TIME = 1.day.to_i
attr_reader :redis
def initialize app
@app = app
@redis = ::Redis.current
end
def call env
dup._call env
end
def _call env
idempotency_key = env[IDEMPOTENCY_HEADER]
if idempotency_key.present?
action = get(idempotency_key)
if action.present?
status = action[:status]
headers = action[:headers]
response = action[:response]
else
status, headers, response = @app.call(env)
response = response.body if response.respond_to?(:body)
payload = payload(status, headers, response)
set(idempotency_key, payload)
end
[status, headers, response]
else
@app.call(env)
end
end
private
def get(key)
data = redis.hgetall namespaced_key(key)
return nil if data.blank?
{
status: data['status'],
headers: Oj.load(data['headers']),
response: Oj.load(data['response'])
}
end
def set(key, payload)
redis.hmset namespaced_key(key), *payload
redis.expire namespaced_key(key), EXPIRE_TIME
end
def payload(status, headers, response)
[
:status, status,
:headers, Oj.dump(headers.to_h),
:response, Oj.dump(response)
]
end
def namespaced_key(idempotency_key)
"#{REDIS_NAMESPACE}:#{idempotency_key}"
end
endLet me save you from the trouble of reading the code and finding the
differences - we added only the redis.expire expire call after setting the
value of the key in the set method. The expire method takes two arguments -
the first one is the key and the second one is the expiry time (in seconds).
Our code will set these keys to expire after 24 hours from the time of setting
them, therefore allowing enough time for the requests to be registered as
completed by the clients.
Of course, if you are implementing a mechanism for idempotent requests for your APIs, the expiration time should be set to your liking, because the data should have a retention period that makes sense for the problem you are solving/facing.
Nevertheless, although our final solution is not very far from our previous ones, whether it’s using a relational databse or a storage in file, Redis allows us to more easily scale the solution while keeping itself clean from stale data.
Wrapping up #
Having all of this in mind, it’s clear to see that idempotent requests can be a useful addition to an API, especially where the nature of the API requires such behaviour. For example, Stripe have idempotent requests for their API , because they are working with payments and this sort of mechanism can be useful for clients to not accidentally replay a charge of a card because of a network issue. Also, in our example, idempotent requests can be useful because you don’t want the client to try to set the same bid twice, due to the nature of an auction (very time sensitive).
In this post we also saw three type of solutions that could work for a mechanism like this one, namely:
- using a relational database;
- using a
YAML::Store; and - using Redis
We also briefly discussed what kind of challenges each of these approaches bring, and we also took a stab at implementing the idempotent requests mechanism using a Rails middleware.
If you would like to see the actual code of this Rails app, and the middleware we built, you can head over to the sample repo on Github, fetch the code and play with it yourself.